如果我们定义观测变量和潜在变量的⼀个联合概率分布,那么对应的观测变量本⾝的概率分布可以通过求边缘概率的⽅法得到。EM算法用于解决具有隐变量的混合模型的极大似然估计问题。
EM算法公式
MLE 问题:$P(x\mid \theta)$
\[\displaystyle \theta_{MLE} = \arg\max_{\theta} \underbrace{\log P(x\mid \theta)}_{\mathrm{log-likelihood}}\]EM算法的公式:
\[\begin{split} \theta^{(t+1)} &= \arg\max_{\theta} \int_{z} \underbrace{P(z\mid x,\theta^{(t)})}_{后验概率} \underbrace{\log P(x,z\mid \theta)}_{完整数据,对数联合概率} \mathrm{d} z\\ &=\arg\max_{\theta}\quad E_{z\mid x,\theta^{(t)}}[\log P(x,z\mid \theta)] \end{split}\]其中$x$是给定数据,$z$是隐变量,$\theta^{(t)}$ 是t时刻的参数。
这个公式包含了迭代的两步:
$1.$ E step:计算 $\log p(x,z\mid \theta)$ 在概率分布 $p(z\mid x,\theta^t)$ 下的期望
$2.$ M step:计算使这个期望最大化的参数得到下一个 EM 步骤的输入
显然,EM是一个递推算法。
EM算法的收敛性证明
收敛性:从 $\theta^{(t)} \rightarrow \theta^{(t+1)}$ 必须满足条件:
\[\log P(x\mid \theta^{(t)}) \le \log P(x\mid \theta^{(t+1)})\]先写通项,显然 \(\log P(x\mid \theta) = \log P(x,z\mid \theta) - \log P(z\mid x,\theta)\)
接下来有技巧性,两边同时对 $P(z\mid x,\theta^{(t)})$ 求积分
\[\begin{split} 左边 = \log P(x\mid \theta) \underbrace{\int_z P(z\mid x,\theta^{(t)})\mathrm{d}z}_{只跟z有关,积分等于1}= \log P(x\mid \theta) \end{split}\]等于什么都没做。
\[\begin{split} 右边 &=\underbrace{ \int_z \log P(x,z\mid \theta) P(z\mid x,\theta^{(t)}) \mathrm{d}z}_{定义为Q(\theta,\theta^{(t)})} - \underbrace{\int_z P(z\mid x,\theta^{(t)}) \log P(z\mid x,\theta) \mathrm{d}z}_{定义为H(\theta,\theta^{(t)})} \end{split}\]因此证明 $\log P(x\mid \theta^{(t)}) \le \log P(x\mid \theta^{(t+1)})$
相当于证明 $Q(\theta^{(t)},\theta^{(t)})-H(\theta^{(t)},\theta^{(t)}) \le Q(\theta^{(t+1)},\theta^{(t)})-H(\theta^{(t+1)},\theta^{(t)})$
由 $\theta^{(t+1)}$ 的定义
\[\begin{split} \theta^{(t+1)} &= \arg\max_{\theta} \int_{z} \log P(x,z\mid \theta)\cdot P(z\mid x,\theta^{(t)}) \mathrm{d} z \\ &= \arg\max_{\theta} Q(\theta,\theta^{(t)}) \end{split}\]很明显,$Q(\theta^{(t+1)},\theta^{(t)}) \ge Q(\theta^{(t)},\theta^{(t)})$.
然后证明 $H(\theta^{(t+1)},\theta^{(t)}) \le H(\theta^{(t)},\theta^{(t)})$, 两项相减:
\[\begin{split} &\ \ \ \ \ \ H(\theta^{(t+1)},\theta^{(t)}) - H(\theta^{(t)},\theta^{(t)})\\&=\int_z P(z\mid x,\theta^{(t)})\cdot \log P(z\mid x,\theta^{(t+1)})dz-\int_z P(z\mid x,\theta^{(t)})\cdot \log P(z\mid x,\theta^{(t)})dz\\ &=\int_z P(z\mid x,\theta^{(t)})\cdot \log {P(z\mid x,\theta^{(t+1)})\over P(z\mid x,\theta^{(t)})}dz\\ \end{split}\]这里如果对 KL 散度熟悉的话,可以直接看出此式等于 $-KL(P(z\mid x,\theta^{(t)}) \Vert P(z\mid x,\theta^{(t+1)}))$
Kullback–Leibler divergence: ${\displaystyle KL(P\parallel Q)=\int _{-\infty }^{\infty }p(x)\log \left({\frac {p(x)}{q(x)}}\right)\,\mathrm{d}x} $
而 $KL(\cdot) \ge 0$ 故 $-KL(P(z\mid x,\theta^{(t)}) \Vert P(z\mid x,\theta^{(t+1)})) \le 0$
所以可知 $H(\theta^{(t+1)},\theta^{(t)}) - H(\theta^{(t)},\theta^{(t)}) \le 0$
也可以使用 Jensen 不等式来解决,由于 $\log(x)$ 为凹函数,可以看出 $E[\log x] \le \log E[x]$.
Jensen 不等式: 若 $f(x)$ 是凸函数,则 $E[f(x)] \ge f(E[x])$
因此
\[\begin{split} &\ \ \ \ \ H(\theta^{(t+1)},\theta^{(t)}) - H(\theta^{(t)},\theta^{(t)})\\ &=\int_z P(z\mid x,\theta^{(t)})\cdot \log {P(z\mid x,\theta^{(t+1)})\over P(z\mid x,\theta^{(t)})}\mathrm{d}z\\ &\le \log \int_z P(z\mid x,\theta^{(t)})\cdot {P(z\mid x,\theta^{(t+1)})\over P(z\mid x,\theta^{(t)})}\mathrm{d}z\\ &=\log \int_z P(z\mid x,\theta^{(t+1)})\mathrm{d}z\\ &=0 \end{split}\]所以 $H(\theta^{(t+1)},\theta^{(t)}) - H(\theta^{(t)},\theta^{(t)}) \le0$.
因此得证 $Q(\theta^{(t)},\theta^{(t)})-H(\theta^{(t)},\theta^{(t)}) \le Q(\theta^{(t+1)},\theta^{(t)})-H(\theta^{(t+1)},\theta^{(t)})$.
故 $\log P(x\mid \theta^{(t)}) \le \log P(x\mid \theta^{(t+1)})$.
K 均值聚类
K 均值算法对应于⽤于⾼斯混合模型的EM算法的⼀个特定的⾮概率极限。
定义每个数据点鱼它被分配到向量 $\mu_k$ 之间的距离的平方和
\[J = \sum_{n=1}^{N} \sum_{k=1}^{K} r_{nk} \Vert x_n - \mu_k \Vert^2\]也称失真度量(distortion measure).
首先选定一组 $\mu_k$ 的初始值,然后分为两阶段:
$1.$ E 步骤:固定 $\mu_k$, 关于 $r_{nk}$ 最小化 $J$. 由于 $J$ 是 $r_{nk}$ 的一个线性函数,不同的 $n$ 对应的项是独立的,因此可以对每个 $n$ 分别进行最优化, 只要 $k$ 的值使得 $\Vert x_n - \mu_k \Vert^2$ 最小,就令 $r_{nk}$ 等于 1。换句话说,我们可以简单地将数据点的聚类设置为最近的聚类中⼼。
$2.$ M 步骤:固定 $r_{nk}$, 关于 $\mu_k$ 最小化 $J$.$J$ 是 $\mu_k$ 的⼀个⼆次函数,通过求导得到其极值点
\[\displaystyle \mu_k = \frac{\sum_n r_{nk}x_n}{\sum_n r_{nk}}\]结果有⼀个简单的含义,即 $\mu_k$ 等于类别 $k$ 的所有数据点的均值。这就是 “K 均值(K-means)”的含义。
由于每个阶段都减⼩了⽬标函数 $J$ 的值, 因此算法的收敛性得到了保证。然⽽,算法可能收敛到 $J$ 的⼀个局部最⼩值⽽不是全局最⼩值。
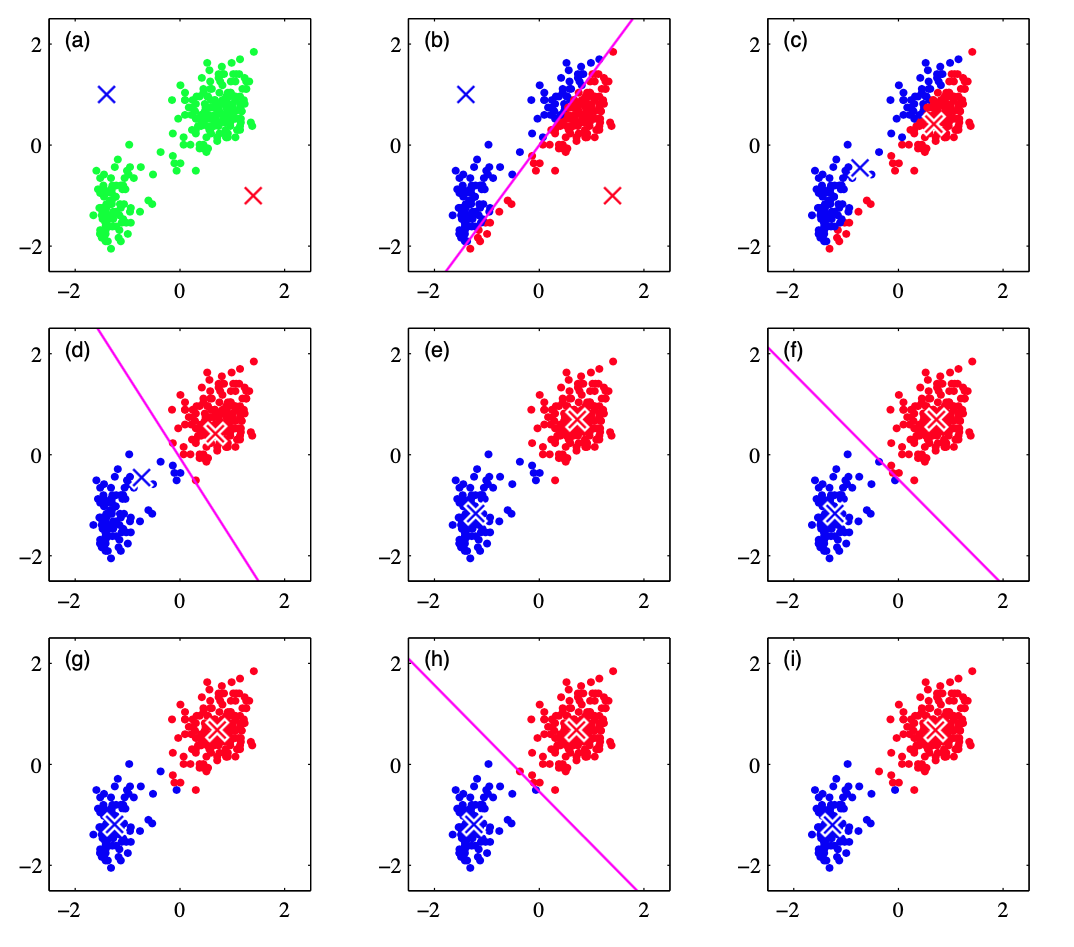 |
|---|
| 在⽼忠实间歇喷泉数据集上进行 K 均值聚类。(a)数据集和分类中心 $\mu_1$ 和 $\mu_2$ (b)在初始的E步骤中,每个数据点根据与哪个中⼼更近来确定类别。这等价于根据两个聚类中⼼的垂直平分线来对数据点进⾏分类。(c)在接下来的M步骤中,每个聚类中⼼使⽤分配到对应类别的数据点重新计算。(d)-(i)给出了接下来的E步骤和M步骤,直到最终收敛。 |
有很多加速 K 均值算法⽅法,⼀些⽅法基于对数据结构的预先计算,例如将数据组织成树结构,使得相邻的数据点属于同⼀个⼦树。另外⼀些⽅法使⽤距离的三⾓不等式,因此避免了不必要的距离计算。
将 Robbins-Monro 步骤应⽤到 K 均值算法,得到顺序更新算法
\[\mu_k^{new} = \mu_k^{old} + \eta_n (x_n-\mu_k^{old})\]其中 $\eta_n$ 是学习率参数,通常令其关于数据点的数量单调递减。
引⼊两个向量 $x$ 和 $x^′$ 之间的⼀个更加⼀般的不相似程度的度量 $V(x, x^′)$ 替代欧氏距离,得到 K 中⼼点算法(K-medoids algorithm)
\[\tilde{J} = \sum_{n=1}^{N} \sum_{k=1}^{K} r_{nk} V(x_n, \mu_k)\]混合⾼斯模型
通过将更基本的概率分布(例如⾼斯分布)进⾏线性组合的这样的叠加⽅法,可以被形式化为概率模型,被称为混合模型(mixture distributions)。
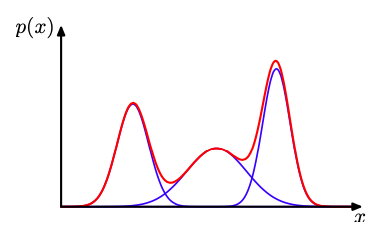 |
|---|
| ⼀维⾼斯混合分布的例⼦ |
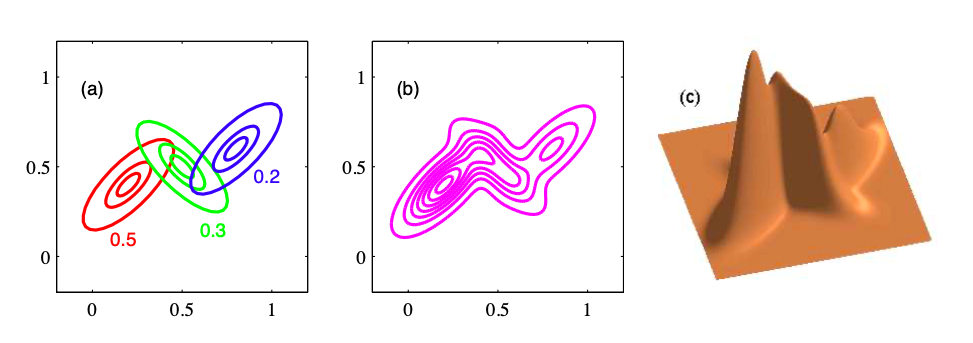 |
|---|
| ⼆维空间中3个⾼斯分布混合的例⼦ |
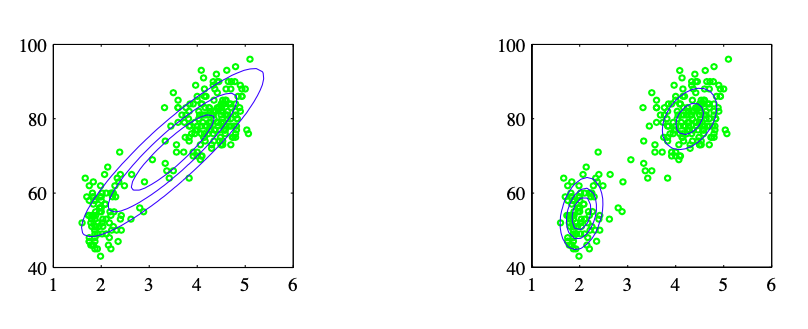 |
|---|
| “⽼忠实间歇喷泉”数据集,由美国黄⽯国家公园的⽼忠实间歇喷泉的272次喷发的测量数据组成。可以看到使用最⼤似然法(左)拟合的单一高斯分布不能描述数据中两个聚集区域,峰值区域内数据稀疏。而使用两个高斯分布线性组合得到的概率分布(右)给出了数据的一个更好的表示。 |
K 个⾼斯概率密度的叠加,形式为
\[p(x) = \sum_{k=1}^{K} \pi_k \cdot \mathcal{N}(x \mid \mu_k,\Sigma_k)\\\quad \sum_{k=1}^{K} \pi_k =1, \quad 0 \le \pi_k \le 1.\]把 $\pi_k = p(k)$ 看成第k个成分的先验概率,密度 $\mathcal{N}(x \mid \mu_k,\Sigma_k)$ 看成以k为条件的x的概率。边缘概率密度为
\[p(x)= \sum_{k=1}^{K} p(k)p(x\mid k)\]根据贝叶斯定理,后验概率 $\gamma_k(x)$ 可以表⽰为
\[\begin{split} \gamma_k(x) &= p(k\mid x)\\ &=\frac{p(k)p(x\mid k)}{\sum_l p(l)p(x\mid l)}\\ &=\frac{\pi_k \mathcal{N}(x\mid \mu_k,\Sigma_k)}{\sum_l \pi_l \mathcal{N}(x\mid\mu_l,\Sigma_l)} \end{split}\]引入一个“1-of-K”变量 $z$, 满足其中⼀个特定的元素 $z_k$ 等于1,其余所有的元素等于0, 有 $K$ 个可能的状态。对于每个观测数据点 $x_n$,对应一个潜在变量 $z_n$.
我们根据边缘概率分布 $p(z)$ 和条件概率分布 $p(x\mid z)$ 定义联合概率分布 $p(x,z)$,对应于下面的图模型。
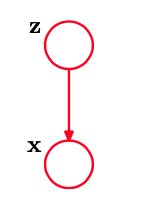 |
|---|
| 混合模型的图形表⽰,其中联合概率分布被表⽰为 $p(x,z)=p(x\mid z)$ 的形式。 |
$z$ 的边缘概率分布根据混合系数 $\pi_k$ 进⾏赋值,即
\[p(z_k=1) = \pi_k\]也可以写成
\[p(z) = \prod_{k=1}^{K} \pi_k^{z_k}\]类似地,给定 $z$, $x$ 的条件概率分布可以写成
\[p(x\mid z_k=1) = \mathcal{N}(x\mid \mu_k, \Sigma_k)\]或者写成
\[p(x\mid z) = \prod_{k=1}^{K} \mathcal{N} (x\mid \mu_k,\Sigma_k)^{z_k}\]从⽽ $x$ 的边缘概率分布可以通过将联合概率分布 $p(z)p(x \mid z)$ 边缘化 $z$ 得到
\[p(x) = \sum_z p(z)p(x\mid z) = \sum_{k=1}^{K} \pi_k \mathcal{N}(x\mid \mu_k,\Sigma_k)\]现在能够对联合概率分布 $p(x,z)$ 操作, ⽽不是对边缘概率分布 $p(x)$ 操作,这会产⽣极⼤的计算上的简化。通过引⼊ EM 算法,即可看到这⼀点。
将 $\pi_k$ 看成 $z_k= 1$ 的先验概率,观测到 $x$ 的条件下,$z$ 的条件概率(后验概率)可以使⽤贝叶斯定理求出
\[\begin{split} \displaystyle \gamma(z_k) = p(z_k=1\mid x) &=\frac{p(z_k=1)p(x\mid z_k=1)}{\sum_{j=1}^{K} p(z_j=1)p(x\mid z_j=1)} \\ &=\frac{\pi_k \mathcal{N}(x\mid \mu_k,\Sigma_k)}{\sum_{j=1}^{K} \pi_j \mathcal{N}(x\mid\mu_j,\Sigma_j)} \end{split}\]$\gamma(z_k)$ 也可以被看做分量 $k$ 对于“解释”观测值 $x$ 的“责任”(responsibility)
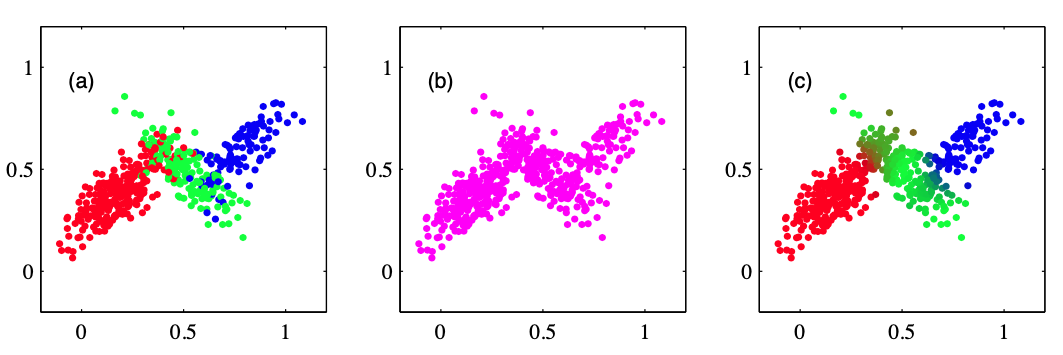 |
|---|
| 从3个⾼斯分布组成的混合分布中抽取的 500 个样本点。(a)从联合概率分布中抽取的样本, 其中 $z$ 的三种状态对应于混合分布的三个分量, ⽤红⾊、绿⾊、蓝⾊表⽰。(b)来⾃边缘概率分布 $p(x)$ 的对应的样本,仅仅将 $z$ 的值忽略,画出 $x$ 的值即可。(a)中的数据集被称为完整的,(b)中的数据集被称为不完整的。(c)同样的样本,颜⾊表⽰与数据点 $x_n$ 关联的责任 $\gamma(z_{nk})$,其中红⾊、蓝⾊、绿⾊所占的⽐重分别由 $\gamma(z_{nk}), k = 1, 2, 3$ 给出。 |
假设我们有⼀个观测的数据集 ${x_1,\dots,x_n}$,将这个数据集表⽰为⼀个 N × D 的矩阵 $X$ ,其中第 $n$ ⾏为 $x_n^T$ 。类似地,对应的隐含变量会被表⽰为⼀个 N × K 的矩阵 $Z$ ,它的⾏为 $z_n^T$. 图模型表示如下:
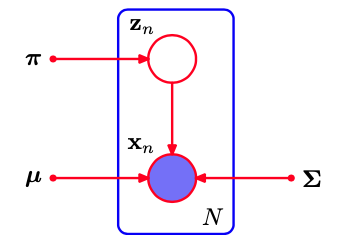 |
|---|
| 一组 $N$ 个独立同分布数据点 ${x_n}$ 的高斯混合模型的图表示,对应的潜在变量为 ${z_n}$, $n=1,\dots,N$ |
对数似然函数为
\[\ln p({X}\mid{\pi},{\mu},{\Sigma}) = \sum_{n=1}^{N} \ln \left\{\sum_{k=1}^{K} \pi_k \mathcal{N}(x_n\mid\mu_k,\Sigma_k) \right\}\]因为对数中存在⼀个求和式,导致参数的最⼤似然解不再有⼀个封闭形式的解析解。⼀种最⼤化这个似然函数的⽅法是使⽤迭代数值优化⽅法,另⼀种⽅法便是EM算法。
在我们讨论如何最⼤化这个函数之前,有必要强调⼀下由于奇异性的存在造成的应⽤于⾼斯混合模型的最⼤似然框架中的⼀个⼤问题。
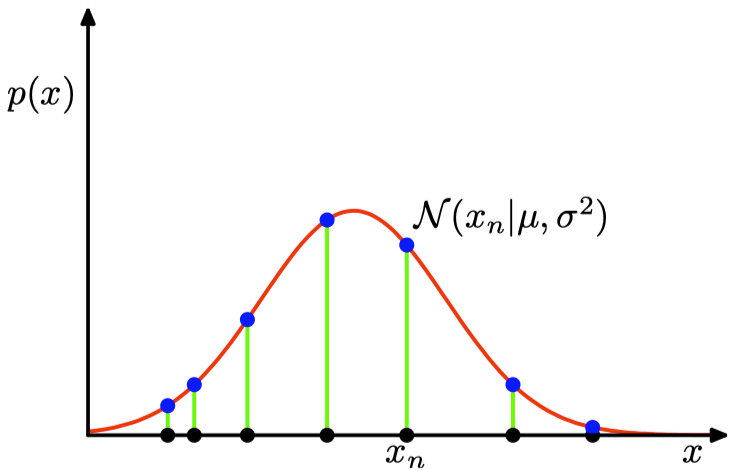 |
 |
|---|---|
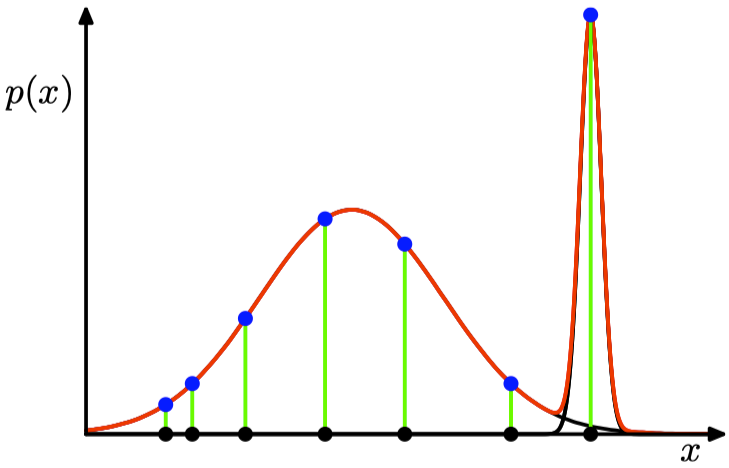
| 红⾊曲线表⽰单⼀的⾼斯概率分布的似然函数。⿊点表⽰数据集 ${x_n}$,似然函数对应于蓝⾊值的乘积。 | 混合⾼斯模型中出现的似然函数的奇异性。⼀个分量会收缩到⼀个具体的数据点,因此会给对数似然函数贡献⼀个不断增加的值。 |
将最⼤似然⽅法应⽤到⾼斯混合模型中时必须避免这种病态解,可以使⽤合适的启发式⽅法来避免这种奇异性,例如,如果检测到⾼斯分量收缩到⼀个点,那么就将它的均值重新设定为⼀个随机选择的值,并且重 新将它的⽅差设置为某个较⼤的值,然后继续最优化。
后⾯会看到,如果我们使⽤贝叶斯⽅法,那么这种困难就不会出现。
⽤于⾼斯混合模型的EM
知识回顾:多元高斯分布
\[\mathcal{N}({x} \mid {\mu}, {\Sigma})=\frac{1}{(2 \pi)^{\frac{D}{2}}} \frac{1}{\mid {\Sigma}\mid ^{\frac{1}{2}}} \exp \left\{-\frac{1}{2}({x}-{\mu})^{T} {\Sigma}^{-1}({x}-{\mu})\right\}\]最大似然估计 \(\mu_{ML} = \frac{1}{N} \sum_{n=1}^{N} x_n\)
\[\Sigma_{ML} = \frac{1}{N} \sum_{n=1}^{N} (x_n-\mu_{ML})(x_n-\mu_{ML})^T\]一种优雅的并且强大的寻找带有潜在变量的模型的最大似然解的方法被称为期望最大化算法(expectation-maximization algorithm),或EM算法。
令似然函数 $\ln p(X\mid \pi, \mu, \Sigma)$ 关于 $\mu_k$ 的导数等于0,有
\[\begin{split} 0 &=\frac{\partial}{\partial \mu_k}\ln p(X\mid \pi, \mu, \Sigma) \\ &= \sum_{n=1}^N \frac{1}{\sum_j \pi_j \mathcal{N}(x_n \mid \mu_j,\Sigma_j)}\frac{\partial}{\partial \mu_k}\sum_{k=1}^{K}\pi_k\mathcal{N}(x_n\mid\mu_k,\Sigma_k)\\ &= \sum_{n=1}^N \frac{\pi_k}{\sum_j \pi_j \mathcal{N}(x_n \mid \mu_j,\Sigma_j)}\frac{\partial}{\partial \mu_k}\mathcal{N}(x_n\mid\mu_k,\Sigma_k)\\ &= \sum_{n=1}^{N} \underbrace{\frac{\pi_k \mathcal{N}(x_n\mid \mu_k,\Sigma_k)}{\sum_j \pi_j \mathcal{N}(x_n \mid \mu_j,\Sigma_j)}}_{\gamma(z_{nk})} \Sigma^{-1}_k(x_n-\mu_k) \end{split}\]其中 $ \mathcal{N}(x_n\mid \mu_k,\Sigma_k) $ 含有指数项,求导等于它本身乘以指数项内部求导 \(\begin{split} \frac{\partial \mathcal{N}(x_n\mid \mu_k,\Sigma_k)}{\partial \mu_k} &= \mathcal{N}(x_n\mid\mu_k,\Sigma_k) \frac{\partial\{\frac{1}{2}(x_n-\mu_k)^T\Sigma_k^{-1}(x_n-\mu_k) \}}{\partial \mu_k}\\ &=\mathcal{N}(x_n\mid\mu_k,\Sigma_k)(-1)\Sigma_k^{-1}(x_n-\mu_k) \end{split}\)
后验概率 $\gamma(z_{nk})$(或者称为“责任”)很⾃然地出现在了等式右侧。两侧同时乘以 $\Sigma_k$ (假设矩阵是⾮奇异的),整理可得
\[\mu_k = \frac{1}{N_k} \sum_{n=1}^N \gamma(z_{nk}) x_n\]其中定义了 $N_k = \sum_{n=1}^N \gamma(z_{nk})$,可以将其看做分配到聚类 k 的数据点的有效样本数量。可以验证所有 $N_k$ 求和等于样本总数量 $N$
\[\begin{split} \sum_k N_k &= \sum_k\sum_n \gamma(z_{nk})\\ &=\sum_{n=1}^{N} \frac{\sum_k\pi_k\mathcal{N}(x_n\mid\mu_k,\Sigma_k)}{\sum_l \pi_l\mathcal{N}(x_n\mid\mu_l,\Sigma_l)}\\ &=\sum_{n=1}^N 1 = N \end{split}\]这个解的形式为对数据集内所有的数据点加权平均得到“第 k 个高斯分量的均值 $\mu_k$” ,权重为后验概率 $\gamma(z_{nk})$ 给出。 $\gamma_(z_{nk})$ 表示分量 k 对生成 $x_n$ 的责任。
类似地,令似然函数 $\ln p(\mathbf{X}\mid\mathbf{\pi},\mathbf{\mu},\mathbf{\Sigma})$ 关于 $\Sigma_k^{-1}$ 的导数等于0
\[\begin{split} 0&=\frac{\partial \ln p(X\mid\pi,\mu,\Sigma)}{\partial \Sigma_k^{-1}} \\ &= \sum_{n=1}^N \frac{\pi_k}{\sum_j \pi_j \mathcal{N}(x_n \mid \mu_j,\Sigma_j)}\frac{\partial}{\partial \Sigma_k^{-1}}\mathcal{N}(x_n\mid\mu_k,\Sigma_k)\\ &= \sum_{n=1}^N \frac{\pi_k}{\sum_j \pi_j \mathcal{N}(x_n \mid \mu_j,\Sigma_j)}( \frac{1}{\sqrt{2\pi}} \cdot \frac{\partial \frac{1}{\sqrt{\Sigma_k^{-1}}}}{\partial \Sigma_k^{-1}}\exp \left\{\frac{1}{2} (x_n-\mu_k) \Sigma_k^{-1}(x_n-\mu_k)^{-1}\right\} \\ &\ \ \ \ \ \ + \mathcal{N}(x_n\mid\mu_k,\Sigma_k) \frac{\partial\{-\frac{1}{2}(x_n-\mu_k)^T\Sigma_k^{-1}(x_n-\mu_k)\}}{\partial \Sigma_k^{-1}} ) \end{split}\]这里用到了两个公式
\[\frac{\partial\mid X^k \mid}{\partial X}=k\mid X^k\mid X^{-T},\quad \frac{\partial a^TXb}{\partial X} = ab^T\]所以原式中比较复杂的两项微分为
\[\frac{\partial \frac{1}{\sqrt{\Sigma_k^{-1}}}}{\partial \Sigma_k^{-1}} = \frac{\partial \mid (\Sigma_k^{-1})^{\frac{1}{2}}\mid}{\Sigma_k^{-1}} = \frac{1}{2} \mid \Sigma_k^{-\frac{1}{2}}\mid\Sigma_k\] \[\frac{\partial\{-\frac{1}{2}(x_n-\mu_k)^T\Sigma_k^{-1}(x_n-\mu_k)\}}{\partial \Sigma_k^{-1}} =-\frac{1}{2}(x_n-\mu_k)(x_n-\mu_k)^T\]于是
\[\begin{split} 0 &= \sum_{n=1}^N \frac{\pi_k}{\sum_j \pi_j \mathcal{N}(x_n \mid \mu_j,\Sigma_j)}(\frac{1}{2} \mathcal{N}(x_n\mid\mu_k,\Sigma_k)\Sigma_k\\ &\ \ \ \ \ \ - \frac{1}{2}\mathcal{N}(x_n\mid\mu_k,\Sigma_k)(x_n-\mu_k)(x_n-\mu_k)^T)\\ &= \frac{1}{2}\sum_{n=1}^{N}\gamma(z_{nk})(\Sigma_k-(x_n-\mu_k)(x_n-\mu_k)^T) \end{split}\]整理得到
\[\Sigma_{k} = \frac{1}{N_k} \sum_{n=1}^{N} \gamma(z_{nk}) (x_n-\mu_k)(x_n-\mu_k)^T\]最后,我们关于混合系数 $ \pi_k$ 最⼤化 $\ln p(\mathbf{X}\mid\mathbf{\pi},\mathbf{\mu},\mathbf{\Sigma})$。考虑限制条件 $\sum_{k=1}^{K} \pi_k =1$,使用拉格朗日乘数法,最⼤化下⾯的量
\[\ln p(\mathbf{X}\mid\mathbf{\pi},\mathbf{\mu},\mathbf{\Sigma}) + \lambda \left( \sum_{k=1}^{K} \pi_k -1 \right)\]得到
\[0 = \sum\limits_{n=1}^N\frac{\mathcal{N}(x_n\mid \mu_k,\Sigma_k)}{\sum_j\pi_j\mathcal{N}(x_n\mid\mu_j,\Sigma_j)} + \lambda\]其中,我们再次看到“责任”这一项。如果我们将两边乘以$ \pi_k $,使用式 $\displaystyle\sum_{k=1}^{K} \pi_k =1$ 对 k 求和,我们会发现 $ \lambda = -N $。使用这个结果消去 $ \lambda $,整理,可得
\[\pi_k = \frac{N_k}{N}\]从而第 k 个分量的混合系数为那个分量对于解释数据点的“责任”的平均值。
 |
|---|
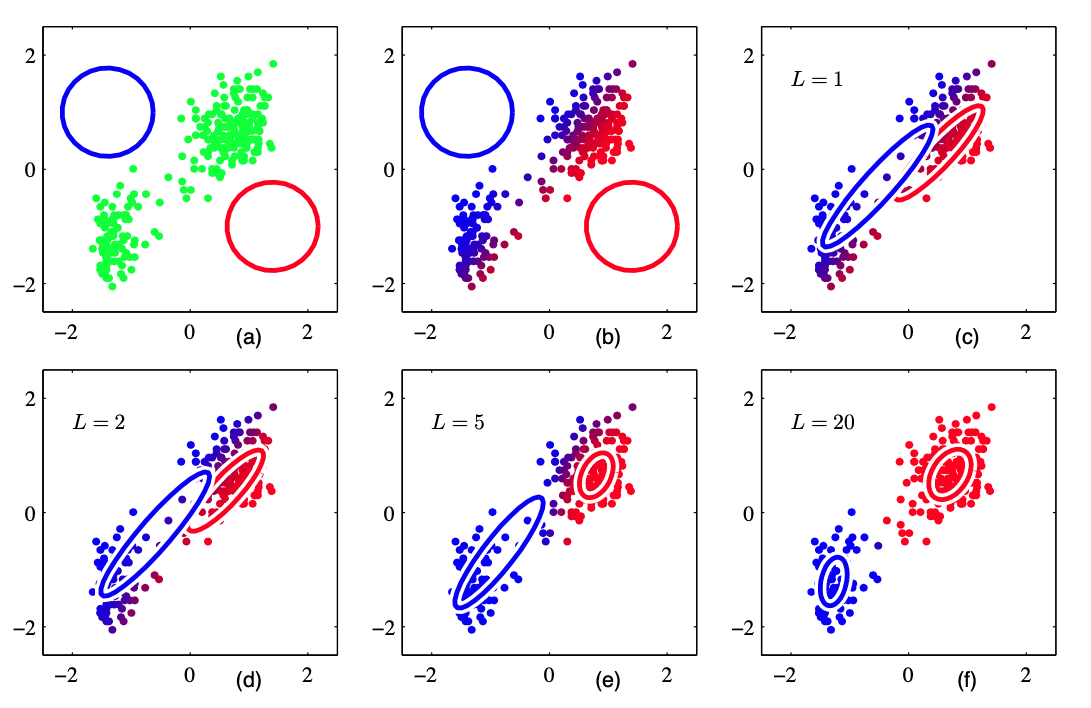
| 对⽼忠实间歇喷泉数据集使⽤EM算法。图(a)⽤绿⾊标记出了数据点,以及初始的混合模型的配置。两个⾼斯分量的⼀个标准差位置的轮廓线分别⽤红⾊圆圈和蓝⾊圆圈标记。图(b)给出了初始E步骤的结果。图(c)给出了第⼀个M步骤之后的结果。图(d),(e)和(f)分别给出了2次、5次、20次完整的EM循环之后的结果。在图(f)中,算法接近收敛。 |
注意,与K均值算法相⽐,EM算法在达到(近似)收敛之前,经历了更多次的迭代,每次迭代需要更多的计算量。 因此,通常运⾏K均值算法找到⾼斯混合模型的⼀个合适的初始化值,接下来使⽤EM算法进⾏调节。协⽅差矩阵可以很⽅便地初始化为通过K均值算法找到的聚类的样本协⽅差,混合系数可以被设置为分配到对应类别中的数据点所占的⽐例。与最⼤化对数似然函数的基于梯度的⽅法相同,算法必须避免似然函数带来的奇异性,即⾼斯分量退化到⼀个具体的数据点。应该强调的是,通常对数似然函数会有多个局部极⼤值,EM不保证找到这些极⼤值中最⼤的⼀个。由于⾼斯混合模型的EM算法⾮常重要,因此我们总结如下。
给定⼀个⾼斯混合模型,⽬标是关于参数(均值、协⽅差、混合系数)最⼤化似然函数。
-
初始化均值 $\mu_k$, 协方差 $\Sigma_k$ 和混合系数 $\pi_k$, 计算对数似然函数的初始值。
-
E 步骤:使用当前参数值计算“责任”。
\(\displaystyle \gamma(z_{nk}) =\frac{\pi_k \mathcal{N}(x_n\mid \mu_k,\Sigma_k)}{\sum_{j=1}^{K} \pi_j \mathcal{N}(x_n\mid\mu_j,\Sigma_j)}\) -
M步骤:使⽤当前的“责任”重新估计参数。
\(\begin{split} \mu_k^{\text{new}} &= \frac{1}{N_k} \sum_{n=1}^N \gamma(z_{nk})x_n\\ \Sigma_k^{\text{new}} &= \frac{1}{N_k} \sum_{n=1}^N \gamma(z_{nk})(x_n-\mu_k^{\text{new}})(x_n-\mu_k^{\text{new}})^T\\ \pi_k^{\text{new}} &= \frac{N_k}{N} \end{split}\)
其中,$N_k = \sum_{n=1}^N \gamma(z_{nk})$. -
计算对数似然函数
\(\ln p(\mathbf{X}\mid\mathbf{\pi},\mathbf{\mu},\mathbf{\Sigma}) = \sum_{n=1}^{N} \ln \left\{\sum_{k=1}^{K} \pi_k \mathcal{N}(x_n\mid\mu_k,\Sigma_k) \right\}\) -
检查参数或者对数似然函数的收敛性。如果没有满⾜收敛的准则,则返回第2步。
潜在变量的作用
EM算法的目标是找到具有潜在变量的模型的最大似然解。我们将所有观测数据的集合记作$ X $,其中第$ n $行表示$ x_n^T $。类似地,我们将所有潜在变量的集合记作$ Z $,对应的行为$ z_n^T $。所有模型参数的集合被记作$ \theta $,因此对数似然函数为
\[\ln p({X} \mid {\theta})=\ln \left\{\sum_ p({X}, {Z} \mid {\theta})\right\}\]注意,这同样适用于连续潜在变量的情形,只需把对 $ Z $ 的求和替换为积分即可。
一个关键的现象是,对于潜在变量的求和位于对数的内部。即使联合概率分布$ p(X,Z\mid \theta) $属于指数族分布,由于这个求和式的存在,边缘概率分布$ p(X\mid \theta) $通常也不是指数族分布。求和式的出现阻止了对数运算直接作用于联合概率分布,使得最大似然解的形式更加复杂。
现在假定对于$ X $中的每个观测,我们都有潜在变量$ Z $的对应值。我们将$ {X, Z} $称为完整(complete)数据集,并且我们称实际的观测数据集 $X$ 是不完整的(incomplete)。假定对这个完整数据的对数似然函数 $\ln p(X, Z\mid \theta)$ 进行最大化是很容易的。
然而,在实际应用中,我们没有完整数据集${X, Z} $,只有不完整的数据$ X $。我们关于潜在变量$ Z $的取值的知识仅仅来源于后验概率分布$ p(Z\mid X, \theta) $。由于我们不能使用完整数据的对数似然函数,因此我们反过来考虑在潜在变量的后验概率分布下,它的期望值,这对应于EM算法中的E步骤(稍后会看到)。在接下来的M步骤中,我们最大化这个期望。如果当前对于参数的估计为$ \theta^{old} $,那么一次连续的E步骤和M步骤会产生一个修正的估计$ \theta^{new} $。算法在初始化时选择了参数$ \theta_0 $的某个起始值。对期望的使用看起来多少有些随意,但是当我们在9.4节更深入地讨论EM算法时,我们会看到这种选择的原因。
在E步骤中,我们使用当前的参数值$ \theta^{old} $寻找潜在变量的后验概率分布$ p(Z\mid X, \theta^{old} ) $。然后,我们使用这个后验概率分布计算完整数据对数似然函数对于一般的参数值$ \theta $的期望。这个期望被记作$ \mathcal{Q}(\theta, \theta^{old}) $,由
\[\begin{split}\mathcal{Q}(\theta, \theta^{old}) &= \mathbb{E}_{Z\mid X,\theta^{old}}\left[\ln p(X,Z\mid \theta)\right] \\&= \sum\limits_Z p(Z\mid X,\theta^{old})\ln p(X,Z\mid \theta) \end{split}\]给出。在M步骤中,我们通过最大化
\[\theta^{new} = \arg\max \mathcal{Q}(\theta, \theta^{old})\]来确定修正后的参数估计$ \theta^{new} $。注意,在$ \mathcal{Q}(\theta, \theta^{old}) $的定义中,对数操作直接作用于联合概率分布$ p(X,Z\mid \theta) $,因此根据假设,对应的M步骤的最大化是可以计算的。
一般的EM算法总结如下。正如我们稍后会看到的那样,每个EM循环都会增大不完整数据的对数似然函数(除非已经达到局部极大值)。
一般的EM算法
给定观测变量$ X $和潜在变量$ Z $上的一个联合概率分布$ p(X,Z\mid \theta) $,由参数$ \theta $控制,目标是关于$ \theta $最大化似然函数$ p(X\mid \theta) $。
- 选择参数$ \theta^{old} $的一个初始设置。
- E步骤。计算$ p(Z\mid X,\theta^{old}) $。
- M步骤。计算$ \theta^{new} $,由 $ \theta^{new} = \arg\max_{\theta} \mathcal{Q}(\theta, \theta^{old})$ 给出。
其中 $ \mathcal{Q}(\theta, \theta^{old}) = \sum\limits_Zp(Z\mid X,\theta^{old})\ln p(X,Z\mid \theta)$。 - 检查对数似然函数或者参数值的收敛性。如果不满足收敛准则,那么令 $ \theta^{old} = \theta^{new}$ 然后回到第2步。
EM算法也可以用来寻找模型的MAP(最大后验概率)解,此时我们定义一个参数上的先验概率分布$ p(\theta) $。在这种情况下,E步骤与最大似然的情形相同,而在M步骤中,需要最大化的量为$ \mathcal{Q}(\theta, \theta^{old}) + \ln p(\theta) $。选择合适的先验概率分布会消除图9.7所示的奇异性。
这里,我们考虑了使用EM算法最大化一个包含离散潜在变量的似然函数。然而,它也适用于未观测的变量对应于数据集里的缺失值的情形。观测值的概率分布可以通过对所有变量的联合概率分布关于缺失变量求和或积分的方式得到。这样,EM算法可以用来最大化对应的似然函数。我们在讨论主成分分析时,会给出这种方法的一个应用。EM算法也适用于数据集随机缺失(missing at random)的情形,即导致某个值缺失的原因不依赖于未观测的值。这种情形有很多,例如当传感器的测量值超过某个阈值时,传感器就不会成功地返回一个值。
重新考虑高斯混合模型
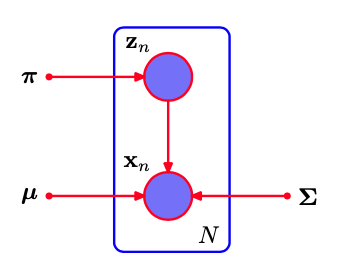
\[\ln p({X} \mid {\pi}, {\mu}, {\Sigma})=\sum_{n=1}^{N} \ln \left\{\sum_{k=1}^{K} \pi_{k} \mathcal{N}\left({x}_{n} \mid {\mu}_{k}, {\Sigma}_{k}\right)\right\}\]我们现在考虑将EM算法的潜在变量观点应用于高斯混合模型,我们现在假定离散变量$ z_n $以及观测变量$ x_n $被观测到,图模型如图所示。
 |
|---|
| 高斯混合模型,我们现在假定离散变量$ z_n $以及观测变量$ x_n $被观测到。 |
现在考虑对完整数据$ {X, Z} $进行最大化。根据
\[p(z) = \prod\limits_{k=1}^K \pi_k^{z_k}\] \[p(x\mid z) = \prod\limits_{k=1}^K\mathcal{N}(x\mid \mu_k,\Sigma_k)^{z_k}\]似然函数的形式为
\[p(X,Z\mid \mu,\Sigma,\pi) = \prod\limits_{n=1}^N\prod\limits_{k=1}^K\pi_k^{z_{nk}}\mathcal{N}(x_n\mid \mu_k,\Sigma_k)^{z_{nk}}\]其中$ z_{nk} $表示$ z_n $的第$ k $个分量。取对数,得到
\[\ln p(X,Z\mid \mu,\Sigma,\pi) = \sum\limits_{n=1}^N\sum\limits_{k=1}^Kz_{nk}\{\ln\pi_k + \ln\mathcal{N}(x_n\mid \mu_k,\Sigma_k)\}\]与不完整数据的对数似然函数进行对比
\[\ln p({X} \mid {\pi}, {\mu}, {\Sigma})=\sum_{n=1}^{N} \ln \left\{\sum_{k=1}^{K} \pi_{k} \mathcal{N}\left({x}_{n} \mid {\mu}_{k}, {\Sigma}_{k}\right)\right\}\]我们看到在$ k $上的求和与对数运算的顺序交换了。对数运算现在直接作用于高斯分布上,而高斯分布本身是指数族分布的一个成员。丝毫不令人惊讶,这种方法产生了最大似然问题的一个简单得多的解,说明如下。首先考虑关于均值和协方差的最大化。由于$ z_n $是一个$ K $维向量,并且只有一个元素等于1,其他所有元素均为0,因此完整数据的对数似然函数仅仅是$ K $个独立的贡献的和,每个混合分量都有一个贡献。于是关于均值或协方差的最大化与单一高斯分布的情形完全相同,唯一的区别是它只涉及到被“分配”到那个分量的数据点的子集。对于关于混合系数的最大化问题,我们注意到由于和限制的存在,不同$ k $值的混合系数相互关联。与之前一样,可以使用拉格朗日乘数法进行优化,结果为
\[\pi_k = \frac{1}{N}\sum\limits_{n=1}^Nz_{nk}\]从而混合系数等于分配到对应分量的数据点所占的比例。
因此我们看到,完整数据的对数似然函数可以用一种简单的方法求出最大值的解析解。然而,在实际应用中,我们并没有潜在变量的值,因此,与之前的讨论一样,我们考虑完整数据对数似然函数关于潜在变量后验概率分布的期望。使用式
\[p(z) = \prod\limits_{k=1}^K \pi_k^{z_k}\] \[p(x\mid z) = \prod\limits_{k=1}^K\mathcal{N}(x\mid \mu_k,\Sigma_k)^{z_k}\]以及贝叶斯定理,我们看到这个潜在变量的后验分布的形式为
\[p(Z\mid X,\mu,\Sigma,\pi) \propto \prod\limits_{n=1}^N\prod\limits_{k=1}^K[\pi_k\mathcal{N}(x_n\mid \mu_k,\Sigma_k)]^{z_{nk}}\]因此后验概率分布可以在$ n $上进行分解,从而$ {z_n} $是独立的。通过观察有向图然后使用d-划分准则,很容易证明这一点。
这样,在这个后验概率分布下,指示值$ z_{nk} $的期望为
\[\begin{split} \mathbb{E}[z_{nk}] &= \frac{\sum\limits_{z_n}z_{nk}\prod_{k'}[\pi_{k'}\mathcal{N}(x_n\mid \mu_{k'},\Sigma_{k'})]^{z_{nk'}}}{\sum\limits_{z_n}\prod_j[\pi_j\mathcal{N}(x_n\mid \mu_j,\Sigma_j)]^{z_{nj}}} \\ &= \frac{\pi_k\mathcal{N}(x_n\mid \mu_k,\Sigma_k)}{\sum\limits_{j=1}^K\pi_j\mathcal{N}(x_n\mid \mu_j,\Sigma_j)} = \gamma(z_{nk}) \end{split}\]它就是$ k $分量对于数据点$ x_n $的“责任”。
于是,完整数据的对数似然函数的期望值为
\[\mathbb{E}_Z[\ln p(X,Z\mid \mu,\Sigma,\pi)] = \sum\limits_{n=1}^N\sum\limits_{k=1}^K\gamma(z_{nk})\{\ln \pi_k + \ln\mathcal{N}(x_n\mid \mu_k,\Sigma_k)\}\]我们现在可以按照下面的方式进行处理。首先,我们为参数$ \mu^{old}, \Sigma^{old}, \pi^{old} $选择某个初始值,使用这些初始值计算“责任”(E步骤)。然后我们保持“责任”固定,关于$ \mu_k,\Sigma_k, \pi_k $最大化对数似然函数的期望(M步骤)。同样的,这会得到$ \mu^{new}, \Sigma^{new}, \pi^{new} $的解析解。这与之前推导的高斯混合模型的EM算法完全相同。